Associating Objects and Their Effects in Video
Through Coordination Games
| 1 Google Research | 2 Shanghai Jiaotong University | 3 Weizmann Institute of Science | 2 VGG, University of Oxford |
| | Paper | Video | Code | |
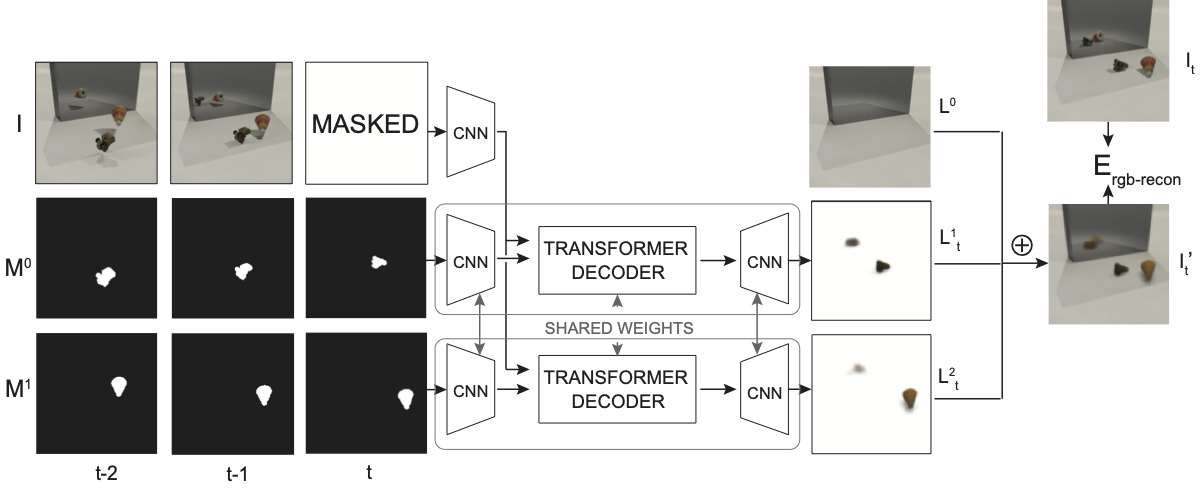 |
Overview of our self-supervised training pipeline to decompose videos into object-centric layers. The input is a short RGB video clip I and masks Mi. The target frame It is masked from the input of the network. The transformer decoder predicts a single output layer from features extracted from the RGB input and the corresponding object mask. The output layers Lit are composited over the background L0 to form the predicted frame I′t , which is compared to the target frame It . No direct supervision is provided for Lit . |
Abstract
We explore a feed-forward approach for decomposing a video into layers, where each layer contains an object of interest along with its associated shadows, reflections, and other visual effects. This problem is challenging since associated effects vary widely with the 3D geometry and lighting conditions in the scene, and ground-truth labels for visual effects are difficult (and in some cases impractical) to collect.
We take a self-supervised approach and train a neural network to produce a foreground image and alpha matte from a rough object segmentation mask under a reconstruction and sparsity loss. Under reconstruction loss, the layer decomposition problem is underdetermined: many combinations of layers may reconstruct the input video.
Inspired by the game theory concept of focal points—or Schelling points—we pose the problem as a coordination game, where each player (network) predicts the effects for a single object without knowledge of the other players' choices. The players learn to converge on the "natural" layer decomposition in order to maximize the likelihood of their choices aligning with the other players'. We train the network to play this game with itself, and show how to design the rules of this game so that the focal point lies at the correct layer decomposition. We demonstrate feed-forward results on a challenging synthetic dataset, then show that pretraining on this dataset significantly reduces optimization time for real videos.
Paper
 |
Associating Objects and Their Effects in Video Through Coordination Games |
Results
Synthetic data pretraining. We train on 2-object videos and show results on 2-object and 4-object videos: |
|||
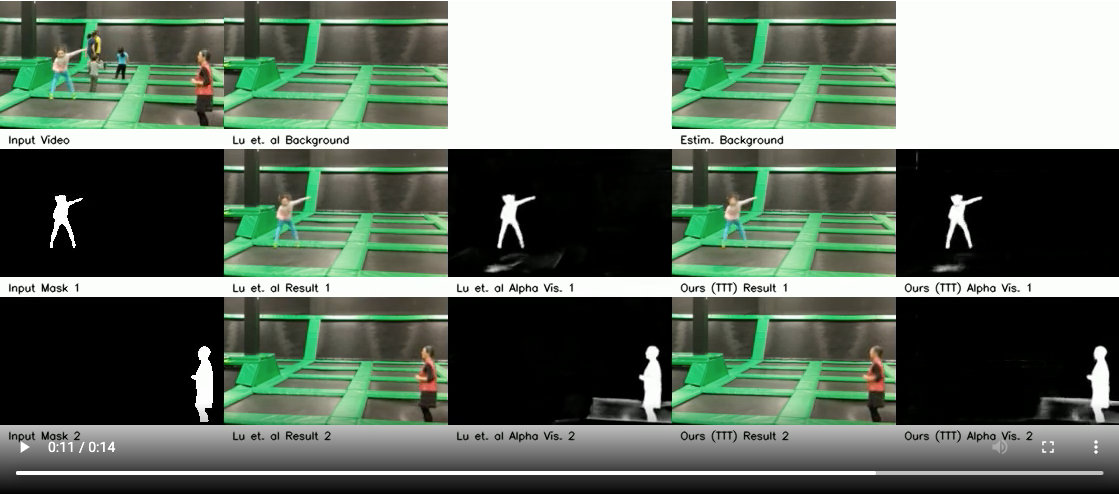
Finetune on real data. After pretraining our model on synthetic data, we finetune it on real videos, achieving results on-par with Lu, et al. [1] despite requiring 1/10th the training time: |
|||
In addition to being faster, our method is more robust to random initializations than Lu, et al. [1]: |
|||
Supplementary Material
 |
Code
|
[code] |
 |
Omnimatte: Associating Objects and Their Effects in Video |
 |
Layered Neural Rendering for Retiming People in Video |
References
[1] |
E. Lu, F. Cole, T. Dekel, A. Zisserman, W. T. Freeman, M. Rubinstein. "Omnimatte: Associating Objects and Their Effects in Video." CVPR 2021 |